每天了解一点不一样的 Swift 小知识
代码截图
小笔记
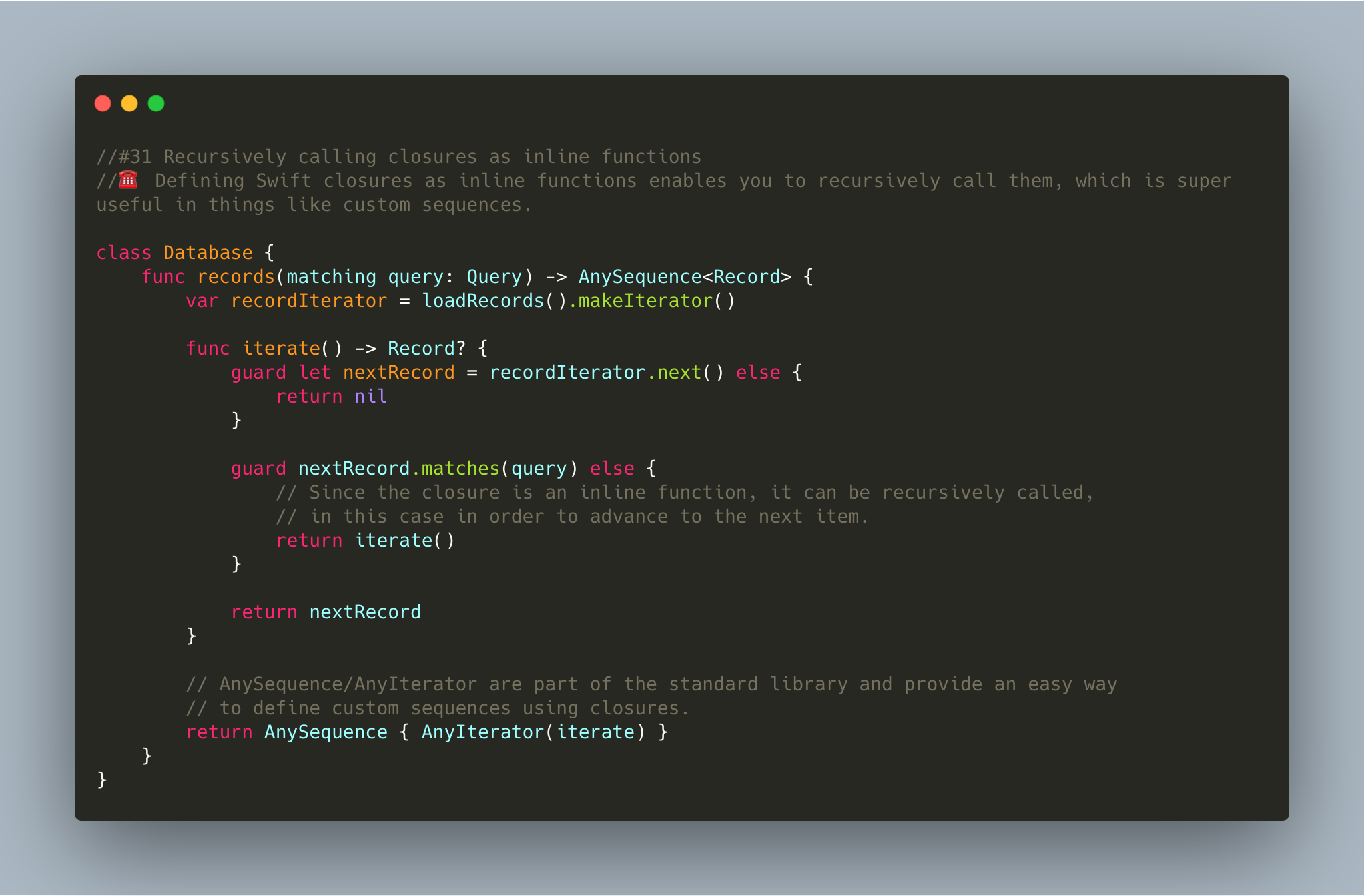
这段代码在说什么
这段代码在 records 函数中内定义了一个名为 iterate 的嵌套函数,当 nextRecord 满足 matches 方法的条件时,它返回 nextRecord 并继续遍历 recordIterator 里的元素,当 nextRecord 不满足 matches 方法的条件时,它通过 iterate 的递归,继续遍历 recordIterator 的元素。
通过这样的方式我们可以记录下 Database 中所有符合条件的 Record 实例。
嵌套函数
在 Swift 中,我们也可以把函数定义在某个函数体中,这样的函数被称作嵌套函数。
默认情况下,嵌套函数是对外界不可见的,但是可以被它们的外围函数调用。一个外围函数也可以返回它的某一个嵌套函数,使得这个函数可以在其他域中被使用。
就像示例代码中的 iterate 就是一个嵌套函数,而 records(matching:) 是一个外围函数。
更多关于嵌套函数的话题可以阅读官方手册的嵌套函数章节。除此之外,我还推荐阅读一下 Matt Neuburg 在 《iOS 10 Programming Fundamentals with Swift》里展示的内联函数在真实工程里的使用场景,很有启发性!
不过今天的内容远不止这些!
似懂非懂的 Sequence 和 Iterator
初看这段代码,不知道你的感受如何?我是觉得好像大体都能看的懂,但很多细节点又不是很明白,例如 AnySequence { AnyIterator(iterate) } 是个什么东西?makeIterator() 返回的对象为什么会有 next() 方法等等。
所以想要完全消化这段代码的全部含义,就得搞清楚 Sequence 和 Iterator 的概念和基本用法。
Sequence 和 Iterator 是什么
在 Swift 的世界中,Sequence 代表的是一系列具有相同类型值的集合,并且提供对这些值的迭代能力。
迭代一个 Sequence 最常见的方式就是 for-in 循环,如下:
for element in someSequence {
doSomething(with: element)
}
Sequece 本身并不是什么基类,只是一个协议,这个协议只有一个必须实现的方法 makeIterator(),它需要返回一个 Iterator 且遵守 IteratorProtocol 类型。它的定义如下:
protocol Sequence {
associatedtype Iterator: IteratorProtocol
func makeIterator() -> Iterator
}
这也就是说,只要提供一个 Iterator 就能实现一个 Sequence,那么 Iterator 又是什么呢?
Iterator 是一个遵守了 IteratorProtocol 协议的实体,它用来为 Sequence 提供迭代能力。这个协议要求声明了一个 next() 方法,用来返回 Sequence 中的下一个元素,或者当没有下一个元素时返回 nil。associatedtype 声明了元素的类型。 它的定义如下:
public protocol IteratorProtocol {
associatedtype Element
public mutating func next() -> Self.Element?
}
对于 Sequence 而言,我们可以用 for-in 来迭代其中的元素,但其实这个功能的背后就是 IteratorProtocol 在起作用。这里我们举一个例子:
let animals = ["Antelope", "Butterfly", "Camel", "Dolphin"]
for animal in animals {
print(animal)
}
// Antelope Butterfly Camel Dolphin
实际上编译器会把以上代码转换成下面的代码:
var animalIterator = animals.makeIterator()
while let animal = animalIterator.next() {
print(animal)
}
实现一个 Sequence 和 Iterator
为了加深理解,我们不妨亲自写一个 Sequence,但就像刚才分析的一样,我们需要先实现一个 iterator
假设我们的 Iterator 要实现这样的功能:它接收一个字符串数组,并可以迭代这个数组中所有字符串的首字母。当数组中的最后一个字符串迭代完毕后,退出迭代。
代码如下所示:
struct FirstLetterIterator: IteratorProtocol {
let strings: [String]
var offset: Int
init(strings: [String]) {
self.strings = strings
offset = 0
}
mutating func next() -> String? {
guard offset < strings.endIndex else {
return nil
}
let string = strings[offset]
offset += 1
return String(string.first!)
}
}
上面这段代码做了两个事情:
- 这个 Iterator 的需要输入一个字符串数组。
- 在
next()中,判断边界,并返回数组中索引为 offset 的字符串的首字母,并把 offset 加 1。
这里省去了 Element 类型的声明,编译器可以根据 next() 的返回值类型推断出 Element 的类型。
有了已经实现好的 Iterator,就可以很简单的用它实现 Sequence,在 makeIterator() 中返回这个 Iterator 即可。
struct FirstLetterSequence: Sequence {
let strings: [String]
func makeIterator() -> FirstLetterIterator {
return FirstLetterIterator(strings: strings)
}
}
现在 Sequence 已经实现好了,可以测试一下效果。 我们可以创建一个 FirstLetterSequence,并用 for-in 循环对其迭代:
for letter in FirstLetterSequence(strings: ["apple", "banana", "orange"]) {
print(letter)
}
// a b o
值类型的 Iterator 和引用类型的 Iterator
一般 Iterator 都是值类型的,值类型的 Iterator 的意思是:当把 Iterator 赋值给一个新变量时,是把原 Iterator 的所有状态拷贝了一份赋值给新的 Iterator,原 Iterator 在继续迭代时不会影响新的 Iterator。
例如用 stride 函数创建一个简单的 Sequence,它从 0 开始,到 9 截止,每次递增 1,即为 [0, 1, 2, …, 8, 9]。然后获取到它的 Iterator,调用 next() 进行迭代。之后我们再做一个赋值操作,创建一个新的 i2,并把 i1 的值赋给 i2,并进行一些操作:
let seq = stride(from: 0, to: 10, by: 1)
var i1 = seq.makeIterator()
i1.next() // Optional(0)
i1.next() // Optional(1)
var i2 = i1
i1.next() // Optional(2)
i1.next() // Optional(3)
i2.next() // Optional(2)
i2.next() // Optional(3)
从打印的结果会发现:i1 和 i2 是两个独立的 Iterator,它们互不影响,赋值时对 i1 做了一份完整的拷贝。所以这里的 Iterator 是一个值类型 Iterator。
当然,我们也可以把任意值类型的 Iterator 变成引用类型的 iterator,而且实施起来也很简单。把任何一个值类型 Iterator 用 AnyIterator 这个包一下就形成了一个引用类型的 Iterator。
结合上面的代码,我们再进行一些操作:
var i3 = AnyIterator(i1)
var i4 = i3
i3.next() // Optional(4)
i4.next() // Optional(5)
i3.next() // Optional(6)
i3.next() // Optional(7)
引用类型的 Iterator,再赋值给一个新的变量后,新的 Iterator 和原 Iterator 在进行迭代时会互相对对方产生影响。
基于函数的 Sequence 和 Iterator
AnyIterator 有一个初始化器,可以传入一个闭包,AnyIterator 会把这个闭包的内容作为调用 next() 时执行的内容。这样创建一个 Iterator 时可以不用创建一个新的 class 或 struct。
例如我们可以这样创建一个斐波那契数列的 Iterator:
func fibsIterator() -> AnyIterator<Int> {
var state = (0, 1)
return AnyIterator {
let upcomingNumber = state.0
state = (state.1, state.0 + state.1)
return upcomingNumber
}
}
然后可以用 AnySequence 来创建 Sequence,AnySequence 也有一个支持传入闭包的初始化器,于是可以把上面的函数名作为参数传入。
let fibsSequence = AnySequence(fibsIterator)
Array(fibsSequence.prefix(10))
// [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
另外,还有一种更简单的方法来创建 Sequence,用 Swift 标准库中的 sequence 函数。这个函数有两个变体:
第一个是 sequence(first:next:)
第一个参数是 Sequence 中的第一个值,第二个参数传入一个闭包作为 next() 的内容。
例如创建一个从大到小的随机数 Sequence。
let randomNumbers = sequence(first: 100) { (previous: UInt32) in
let newValue = arc4random_uniform(previous)
guard newValue > 0 else {
return nil
}
return newValue
}
Array(randomNumbers)
// [100, 90, 60, 35, 34, 21, 3]
第二个变体是 sequence(state:next:),这个要更为强大,它可以在迭代过程中修改状态。
let fibsSequence2 = sequence(state: (0, 1)) { (state: inout (Int, Int)) -> Int? in
let upcomingNumber = state.0
state = (state.1, state.0 + state.1)
return upcomingNumber
}
Array(fibsSequence2.prefix(10))
// [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
sequence(frist:next:) 和 sequence(state:next:) 的返回值类型是一个 UnfoldSequence。
可能有人会好奇 unfold 是一个什么概念?其实它出自函数式编程的范畴里,在函数式编程中有 fold 和 unfold 的概念。fold 是把一系列的值变为一个值,例如 reduce 就是一个 fold 操作。unfold 是 fold 的反操作,把一个值展开成一系列的值。
再回首
结合着嵌套函数,Sequence 和 Iterator 这些知识点,让我们再重新阅读一下最开始的代码片段,不知道这一次你是否有了什么新的感受?
如何有任何疑问或者建议,欢迎交流!